Introduction to Amazon Glacier Service this is the blog topic in that you will learn S3 and Glacier Select, Amazon Glacier, Storage Pricing & Other Storage-Related Services like Amazon Elastic File System, AWS Storage Gateway, AWS Snowball etc
S3 and Glacier Select
AWS provides a different way to access data stored on either S3 or Glacier: Select. The feature lets you apply SQL-like queries to stored objects so that only relevant data from within objects is retrieved, permitting significantly more efficient and cost-effective operations. One possible use case would involve large CSV files containing sales and inventory data from multiple retail sites. Your company’s marketing team might need to periodically analyse only sales data and only from certain stores. Using S3 Select, they’ll be able to retrieve exactly the data they need—just a fraction of the full data set—while bypassing the bandwidth and cost overhead associated with downloading the whole thing.
Related Products:– AWS Certified Solutions Architect | Associate
Amazon Glacier
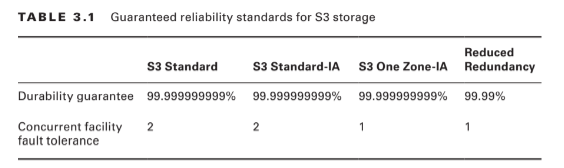
At first glance, Glacier looks a bit like just another S3 storage class. After all, like most S3 classes, Glacier guarantees 99.999999999 percent durability and, as you’ve seen, can be incorporated into S3 lifecycle configurations.Nevertheless, there are important differences. Glacier, for example, supports archives as large as 40 TB rather than the 5 TB limit in S3. Its archives are encrypted by default, while encryption on S3 is an option you need to select; and unlike S3’s “human-readable” key names, Glacier archives are given machine-generated IDs. But the biggest difference is the time it takes to retrieve your data. Getting the objects in an existing Glacier archive can take a number of hours, compared to nearly instant access from S3. That last feature really describes the purpose of Glacier: to provide inexpensive long-term storage for data that will be needed only in unusual and infrequent circumstances.
Storage Pricing
To give you a sense of what S3 and Glacier might cost you, here’s a typical usage scenario. Imagine you make weekly backups of your company sales data that generate 5 GB archives. You decide to maintain each archive in the S3 Standard Storage and Requests class for its first 30 days and then convert it to S3 One Zone (S3 One Zone-IA), where it will remain for 90 more days. At the end of those 120 days, you will move your archives once again, this time to Glacier, where it will be kept for another 730 days (two years) and then deleted.Once your archive rotation is in full swing, you’ll have a steady total of (approximately) 20 GB in S3 Standard, 65 GB in One Zone-IA, and 520 GB in Glacier. Table 3.3 shows what that storage will cost in the US East region at rates current at the time of writing.

Of course, storage is only one part of the mix. You’ll also be charged for operations including data retrievals; PUT, COPY, POST, or LIST requests; and lifecycle transition requests. Full, up-to-date details are available at https://aws.amazon.com/s3/pricing/.
Other Storage-Related Services
It’s worth being aware of some other storage-related AWS services that, while perhaps not as common as the others you’ve seen, can make a big difference for the right deployment.
Amazon Elastic File System
The Elastic File System (EFS) provides automatically scalable and shareable file storage. EFS-based files are designed to be accessed from within a virtual private cloud (VPC) via Network File System (NFS) mounts on EC2 instances or from your on-premises servers through AWS Direct Connect connections. The object is to make it easy to enable secure, low-latency, and durable file sharing among multiple instances.
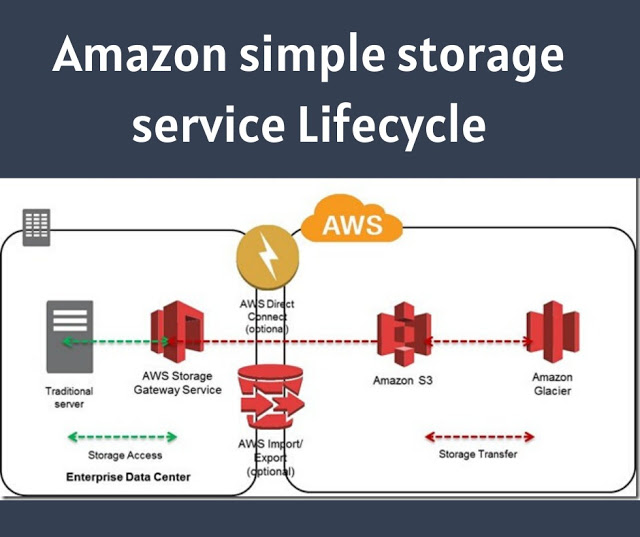
Also Read:– Amazon simple storage service Lifecycle
AWS Storage Gateway
Integrating the backup and archiving needs of your local operations with cloud storage services can be complicated. AWS Storage Gateway provides software gateway appliances (based on VMware ESXi, Microsoft Hyper-V, or EC2 images) with multiple virtual connectivity interfaces. Local devices can connect to the appliance as though it’s a physical backup device like a tape drive, while the data itself is saved to AWS platforms like S3 and EBS.
Read More : https://www.info-savvy.com/overview-of-amazon-glacier-service/
————————————————————————————————————
This Blog Article is posted byInfosavvy, 2nd Floor, Sai Niketan, Chandavalkar Road Opp. Gora Gandhi Hotel, Above Jumbo King, beside Speakwell Institute, Borivali West, Mumbai, Maharashtra 400092
Contact us – www.info-savvy.com